Building the Living Museum of Xylemic
"I saw the angel in the marble and carved until I set him free" — Michaelangelo (or so I've been told)
After writing a fitting (at least, to me) farewell letter to Twitter, I downloaded my Twitter archive and deleted my account.
That was August last year. Since then I have paranoidly backed up the archive (on the Mac I am writing this essay on, on a Google Drive and on my Mac Mini). I always wanted to do something with the data, but it was really a firehose to sort through.
My original idea was to strip down the data into a single JSON string I serve over the wire and query via really nasty substring matches. Suboptimal, to be sure, but there was just something horrendously simple about shipping raw JSON to the browser and calling it a day.
Dissatisfied with this idea, I shelved the idea and spent some time hibernating in Nairobi.
I'm back now, and I have done something with all that data, and I call it The Living Museum of Xylemic.

An Idolatrous Premise
Twitter was the place for pithiness. Was. When the character limit was ~140, I had a lot of fragmented thoughts, and sometimes a sliver of brilliance splurted through. By the time the word count ballooned, I rarely needed to write a thread as my entire frame of mind could fit in a tweet!
What this does to the data is that some tweets are sparse, some dense, and others are so noisy as to throw off both a searcher and a curator!
A searcher and a curator is what The Living Museum of XYLEMIC is. If my words are inert, the Museum quickeneth.
The Living Museum works simply:
- Guests visit the website
- Ask questions about XYLEMIC's writings and thoughts
- The Stochastic Curator pores through the archive searching for tweets (and Substacks — more on this), using the most relevant findings to answer the question.
Sounds simple enough. The development, however, was...enlightening.
Data preparation
Because this is explicitly an "AI engineering" project, we have to prepare the data. Being a novice data engineer, I approached this somewhat naively. I first parsed out media, stripped out metadata and extraneous information (Twitter Moments used to be a thing, and they still pack the data in the archive).
I stripped out old quote retweet-styled tweets (if you're a Twitter OG, you know them—prefixing "RT" on someone's tweet to let them know you're retweeting them). The problem was that the curator would end up attributing someone else's words to me.
On Twitter, I responded to a lot of CuriousCat questions, which means there are many tweets in my database that are half anonymous question, half my response. It was also crucial to note the shape of these peculiar entries, and add a small disambiguation note downstream to the curator.
The good news is that because I wasn't working with BLOBs, just raw tweet data, it was easy to host the raw data.
The Stochastic Curator
Now, how do we search and comb and filter and curate this tidy mess?
Two ways:
- Keyword search, and
- Semantic search
Keyword search is cheap and easy to implement. Match keywords against a corpus of text, and find the most relevant ones — there are simple ML techniques for doing this. So simple they're toys at this point.
For the museum, we do a full-text-search and transform the user's query into a precise set of keywords, typically looking like this:
User asks: "What does XYLEMIC think of Israel and Palestine?"
Our FTS decomposer takes that query, and returns a match string that reads something like this:
"what" "does" "xylemic" "think" "of" "israel" "and" "palestine"
Yikes — keywords like "what", "does", etc, are noisy. They will pull in irrelevant results into the DB.
I maintain a list of "STOP WORDS", like "what", which get filtered out of the query automatically, which will leave us with something like:
"xylemic", "israel", "palestine".
...except that "xylemic" is also a stop word.
So, just "Israel" and "Palestine". Perfect, these are the keywords we need.
After this, I do two things:
- Send the Israel and Palestine keywords to a small language model that expands the terms for morphological similarities, synonyms, etc. We get back a list of keywords that may look like this: ["antisemitism", "zionism", "netanyahu"] for example.
- Those keywords are then used for semantic retrieval. I embedded my tweets and uploaded the vector embeddings to a cloud service.
So we run keyword retrieval and semantic retrieval at once over the same data. The results are then re-ranked, sliced (TOP_K=25), and passed to a research agent.
The research agent looks at the keywords and decides if this is sufficient. The research agent may also see a completely different and promising angle to explore, which prompts the research agent either to come up with new search queries, or to send the selected tweets to the actual writer agent.
Finally, there is a third agent that does basic input hygiene (to make sure queries are about XYLEMIC, for example).
These three agents (input guard, research agent and writer agent) combine to form The Stochastic Curator.

Above is a sample curatorial trace (all essays by The Stochastic Curator have this trace).
Archive Essays
If you want to find out what I have said about something, you can ask, and the curator will prepare a well-cited essay answering your question:

The essays are prepared, and a hash of your query is used to create procedural ASCII art. This is what a response to your query about XYLEMIC returns:
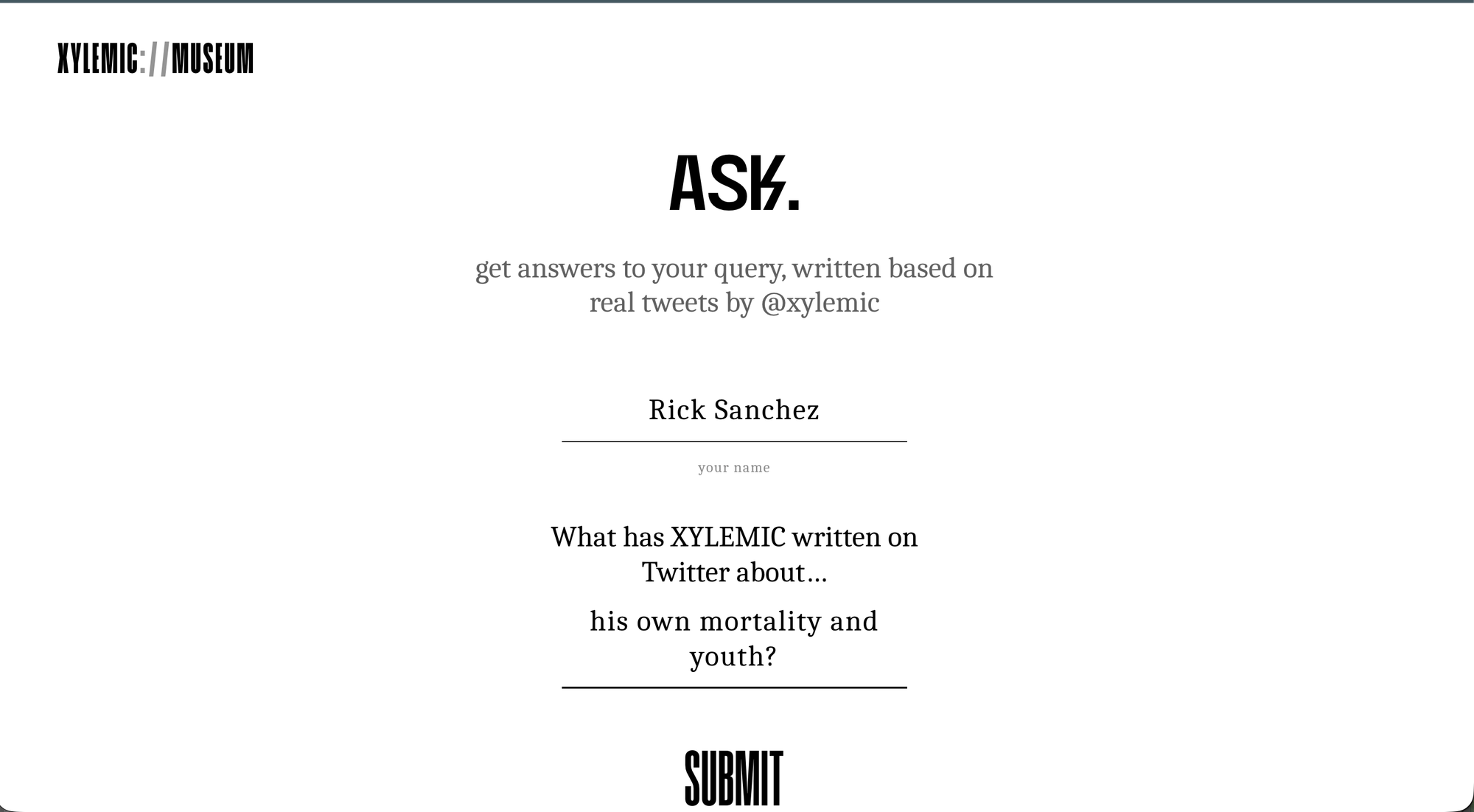

The ASCII art here is generated from a HASH of "his own mortality and youth".

Citations are embedded and anchored to paragraphs, and we have a headline quote somewhere in the middle, rendered in what I thought was a nice handwriting font.
Design and Process
I rarely get to vibe-code in my daily life (where vibe-coding, as I understand it, is chatting with an LLM that generates reams of dubious code which you don't check).
For this project, I decided to let Claude do a first pass over the codebase, then I'll take the generated code and apply my own design and engineering judgment over it.
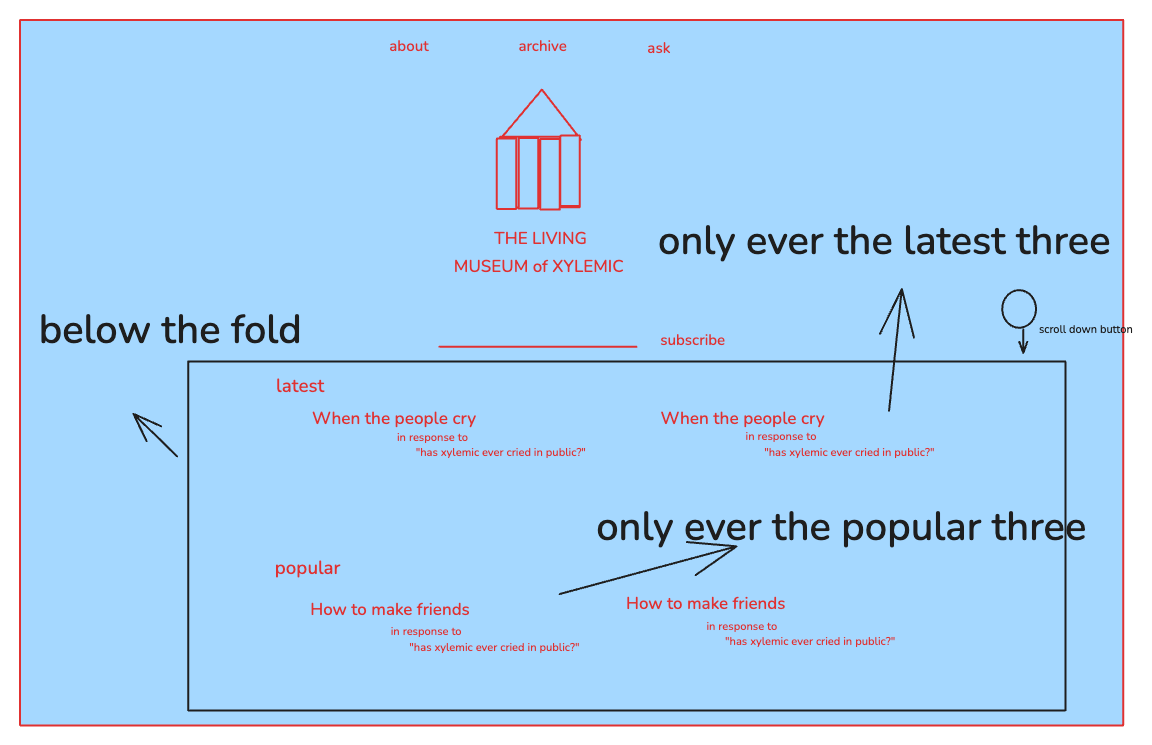
I use Excalidraw as a quick way to show Claude in lo-def how I am thinking of layouts and composition.

My final UI looks nothing like my early sketches, but I am sharing them here as this was the beginning of my exploration.

Claude took these and made something usable. While Claude was working on the backend, I fired open OpenDesign (the open-source answer to Claude Design, which I still don't have access to).
Both Claude Code and OpenDesign (which is really Claude in another harness) made a few design passes, and I liked some of what they did.


The Fuzzy Compiler
I'm not here to debate what is AI slop or isn't. All I know is LLMs are fuzzy compilers, and they're good at sampling what is common knowledge and arriving at a fuzzy mix of the hoi polloi.
That's...great for surveying the land (and bootstrapping an opening project), but if you are to build anything in the world, you have to eventually do a slop pass, esp if the first draft came from an LLM.
Sigh. So I opened Figma...
I am no designer, but I am more motivated to have designed my own project than anything. I pored over the pages, and began to redesign and rewrite them.

Now it's live. Play with it, and share with friends (not sure how useful it'll be to people who have no idea who XYLEMIC is).
Seize the day.
Announcement
If you're reading this and are confused as to what "Life of Mogwai" is, let me explain:
- You are receiving this email because you subscribed to Craft Overflow on Substack
- I am archiving Craft Overflow, and consolidating all my writing under one website and newsletter (this is it)
- Because I am consolidating all my writing, you will not always get only computer/software essays, but my generic/general musings. This was a software engineering essay, but the next one might be a poem about earlobes.
- My original contract with you as reader was on Craft Overflow, so if you don't like this, please unsubscribe. I promise I won't hate.
However, if you rock with me, please tell your friends about Life of Mogwai!
Tinkerer building while thinking.